
")
Within the first a part of this text, I write in regards to the enterprise architecture-related the reason why corporations take into account Databricks as an acceptable Large Knowledge platform. This time, I wish to spotlight the small print associated to creating a Large Knowledge resolution and what Databricks options make it a strong improvement ecosystem. There are the next areas which I take into account essential:
the event setting targeted on the Databricks workspace,
the Delta Lake element that replaces previous Hive,
infrastructure provisioning, automations, and administration.

Fashionable Large Knowledge Platform – why do enterprises select Databricks?
The primary gateway to Databricks that I take advantage of day-after-day for improvement is Databricks Workspace – a user-friendly and extremely intuitive net software. That is the place you’ll be able to view your workflows, job runs, preview logs, and entry the Spark UI. There, you’ll be able to view the compute clusters and their configuration, in addition to all of the autoscaling occasions occurring on the clusters. Workspace can also be a spot the place you’ll be able to write and run SQL queries, that are essential for primary profiling or figuring out data-related points. After all, Databricks gives you with a JDBC connector so you may also open connections and execute queries out of your favourite SQL consumer or programming IDE instantly. Nonetheless, doing this out of your browser could also be handy.
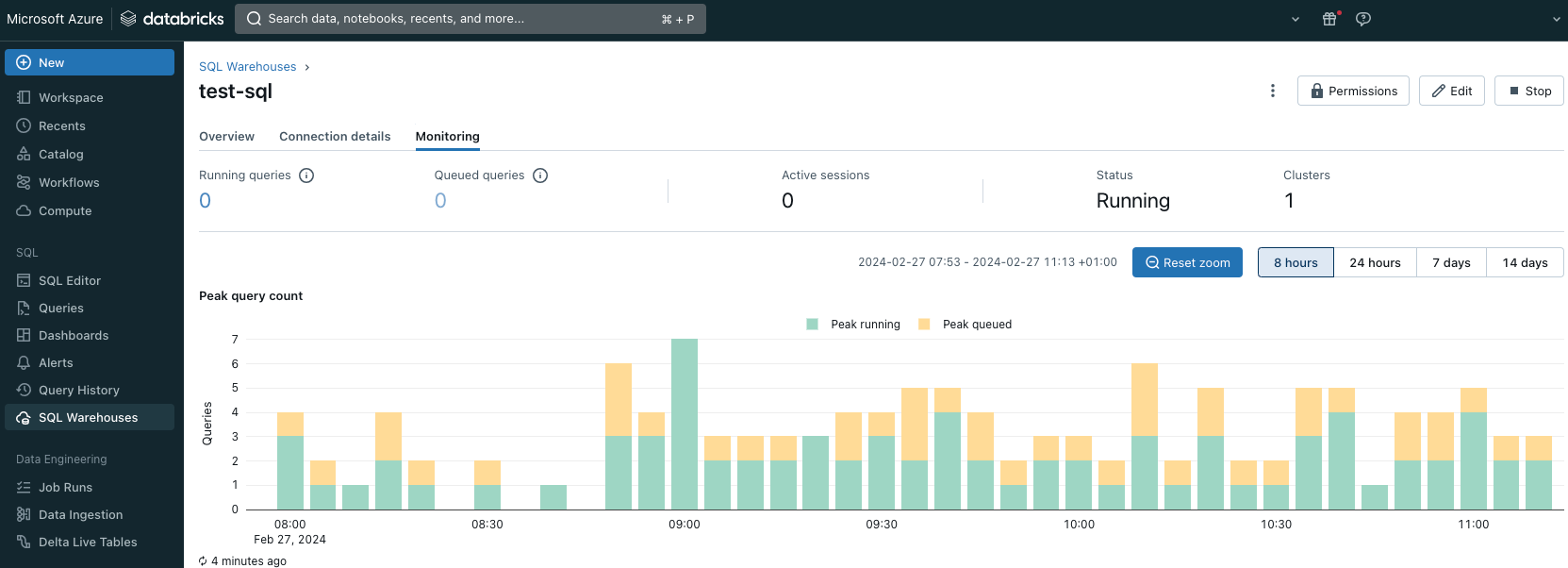
The workspace gives you with entry to notebooks. You’ll be able to write the Spark code within the pocket book utilizing a number of languages (Scala, Python, R, SQL). Notebooks are an ideal experimentation setting and, in actual fact, can be utilized equally to the Spark Shell. In case it is advisable prototype one thing or debug on the cluster, you’ll be able to fairly simply write a code that may be run instantly on the cluster and entry the info in your tables. Nonetheless, it is usually attainable, and even really helpful by Databricks, to encapsulate the pocket book right into a workflow and use notebooks to run code even in a manufacturing setup. For a lot of programmers, that might really sound like a nightmare, but when you consider it, it might be a invaluable function, particularly when built-in along with your code repository.
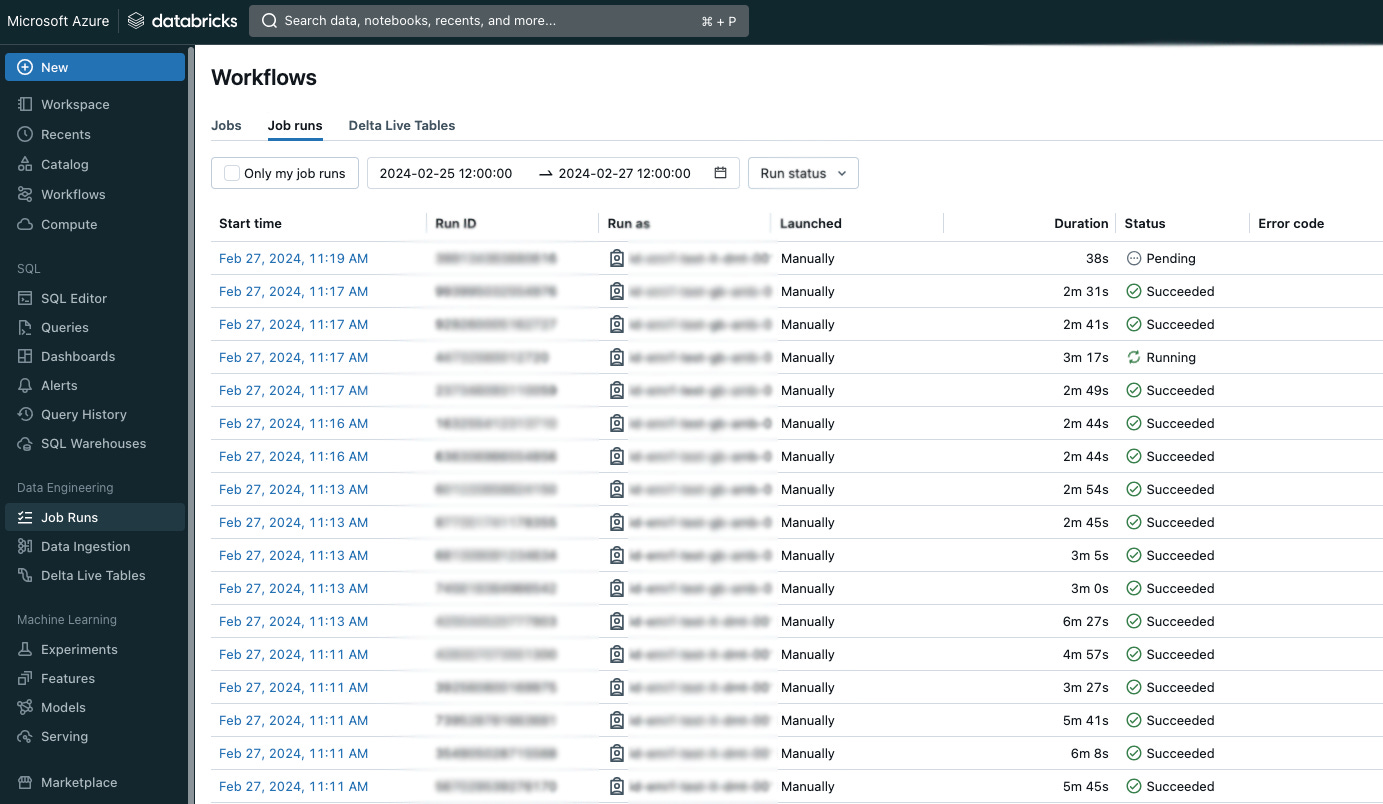
Aside from that, the workspace gives the visualization and dashboarding capabilities. There’s additionally Machine Studying integration that covers mannequin registry and serving capabilities, making Databricks Workspace a robust and handy improvement setting. It’s clearly seen that Databricks invests in extra data-related options to make a completely operational knowledge platform that may assist all huge knowledge, knowledge engineering, and knowledge science use circumstances.
Okay, however what are the general advantages of this device? I’m positive that for a lot of of you, particularly programmers, these are the options you may simply get by utilizing various instruments. Nearly all of these options can be found within the classical Hadoop ecosystem anyway, simply in a extra classic fashion. None of those capabilities are a recreation changer? I do agree.
One other factor you get after switching from Hadoop to Databricks is the Delta Lake know-how. Delta Lake is, in actual fact, a alternative for Hive and Impala that brings a set of essential enhancements. The important thing belongings you get are the next:
ACID Transactions – Delta Lake gives ACID (Atomicity, Consistency, Isolation, Sturdiness) transactions, that are essential for sustaining the consistency and reliability of information.
Schema evolution – you’ll be able to evolve your schema over time and implement it, which isn’t so simple with Hive.
Time Journey (knowledge versioning) – you’ll be able to roll again and restore your desk to one in all its earlier variations. Because of the built-in versioning, compliance necessities are simply met.
Optimize for Spark – Delta Lake is totally appropriate with Spark and designed with Spark in thoughts. It affords many choices to regulate the efficiency of your Spark workloads.
Databricks Unity Catalog – it replaces the normal Hive metastore, simplifying entry and metadata administration; additionally, it performs an essential position in efficiency optimizations.
All of the above options make the Delta Lake know-how a positive successor to Hive, and in the meanwhile, this can be a extra handy option to retailer knowledge when utilizing Spark. You don’t must invalidate metadata tables anymore, simply to say one in all many advantages after shifting to Delta. After all, when migrating from conventional Hadoop, chances are you’ll encounter some small inconsistencies, equivalent to points with concurrent updating of partitions that must be extra fastidiously managed in your code. However general, this modification is useful. Databricks is consistently investing in Delta to make it an much more highly effective knowledge retailer. Databricks is commonly talked about as a direct competitor of Snowflake as a consequence of its consistently improved SQL assist or, to be extra exact, its interface for executing SQL queries on Spark.
However neither the event ecosystem nor Delta Lake could be in comparison with the final set of options I need to describe. They’re associated to infrastructure administration and its first rate simplification.
Databricks is cloud-native, and it leverages the advantages of cloud infrastructure. The compute clusters are designed to autoscale primarily based on the scale of the workload. After all, the clusters don’t develop infinitely however moderately based on predefined insurance policies. That is often configured by DevOps groups utilizing the Terraform scripts. Within the coverage, we outline the scale of the occasion/machine the clusters ought to be constructed of, sure permissions, and auto-scaling conduct (limits, time after which a cluster scales to zero, and extra). After granting entry to the insurance policies to the builders, they’re allowed to create the compute clusters for his or her jobs or notebooks utilizing Databricks Workspace.
With the above comes one other essential benefit – computational isolation. Every job, pocket book, or developer can have a devoted cluster created that completely helps a given workload. If the cluster isn’t used for some minutes, it scales to zero and prices you nothing. Because of this, enterprises that have processing peaks and undergo from useful resource cannibalization for his or her on-premise knowledge facilities can profit from dynamic scaling and will not be affected by elevated computation useful resource calls for. It is a large recreation changer and an actual profit. What’s much more lovely, in case your insurance policies are configured correctly, this won’t value you greater than on-premise infrastructure and conventional Hadoop clusters.
All of the Databricks artifacts, equivalent to clusters, workflows/jobs, and every part associated to permissions, are supported by APIs which might be excellent for automating the deployment of Spark pipelines. Your CI/CD pipelines can replace the variations of your code executed by the Databricks workflows every time the brand new code is constructed. You’ll be able to spin up new Databricks workspaces or automate new undertaking setups throughout the workspaces. The power to handle this each day is one other recreation changer that may finally considerably cut back upkeep prices.
Databricks affords a extremely handy setting for working with Spark when processing Large Knowledge. Improvement setting is trendy and user-friendly. You’ll be able to carry out quite a lot of duties with out leaving the net browser. The entire set of APIs and trendy (or, if you happen to desire, DevOps-centric) strategy to sustaining the workspaces, tasks, and underlying infrastructure makes it extra handy to effectively ship Spark pipelines. And all of these don’t have to be costlier than on-premise Hadoop clusters. Databricks ought to be thought of by Spark-based organizations as the subsequent platform emigrate to after Hadoop.