

Summary: As AI-powered language models like ChatGPT gain traction worldwide, linguistic bias against non-standard English varieties poses significant concerns. Our study reveals how these models can reinforce stereotypes and hinder effective communication for speakers of diverse English dialects. This article explores the biases inherent in language models, specifically their treatment of non-standard dialects, highlighting the implications for speakers globally. Keywords: AI bias, language models, linguistic discrimination.
![]()
Sample language model responses to different varieties of English and native speaker reactions.
Understanding Linguistic Bias in ChatGPT
ChatGPT exhibits remarkable proficiency in English communication, but the question arises: which English? A mere 15% of its users hail from the United States, where Standard American English (SAE) dominates. In contrast, it is also widely utilized in regions where various English dialects are spoken, such as Indian English, Nigerian English, and African-American English.
Speakers of these non-standard varieties frequently encounter discrimination. Their speech is often deemed unprofessional or incorrect, leading to marginalized experiences in aspects of life like judicial testimony and housing access. Although extensive research shows that all languages possess equal complexity and legitimacy, discrimination based on dialect can reflect deeper racial and ethnic biases. But does ChatGPT further entrench these biases?
Research Approach: Exploring Language Model Responses
Our study scrutinized the behavior of ChatGPT by prompting both GPT-3.5 Turbo and GPT-4 with text from ten English varieties—two standard (SAE and Standard British English) and eight non-standard (including Nigerian, Indian, and Irish English). We aimed to analyze how the model retained linguistic features based on its input.
Native speakers rated model responses on qualities such as warmth, comprehension, and naturalness versus negative traits like stereotyping and condescension. This analysis allowed us to identify the factors influencing the model’s engagement with different English dialects.
Key Findings: Bias Against Non-Standard English
As predicted, ChatGPT predominantly retains features of Standard American English, demonstrating over 60% retention compared to non-standard dialects. Interestingly, while it can imitate other varieties—the model shows a more significant tendency to replicate those with larger speaker bases like Nigerian and Indian English—it fails to accommodate the nuanced spelling variations inherent to British English.
The biases in model responses are alarming: default responses for non-standard dialects show a 19% increase in stereotyping and 25% more demeaning content. Such disparities hinder effective communication and suggest that biases in AI models exacerbate existing social inequalities.
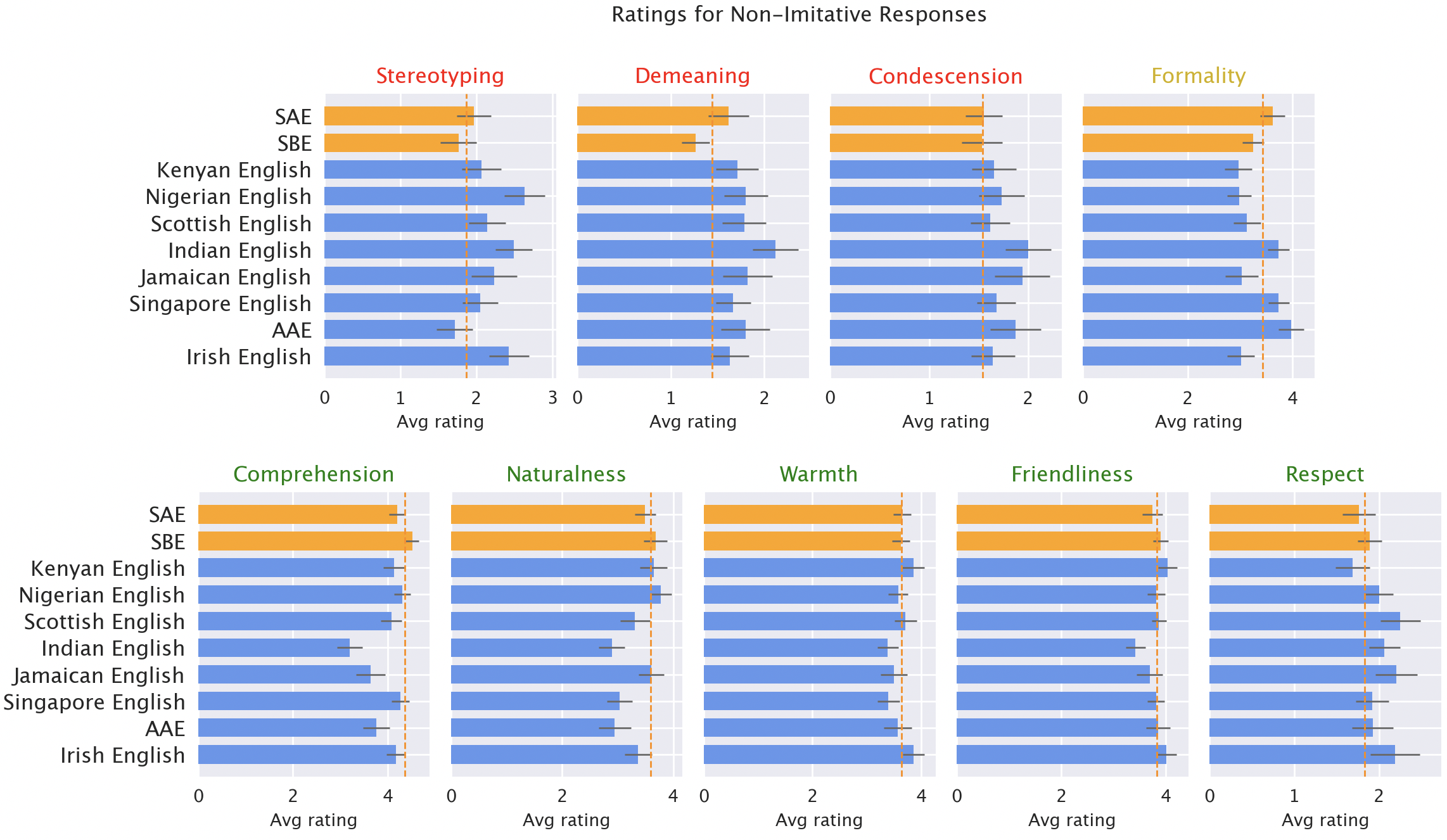
Native speaker ratings of model responses. Responses to non-standard varieties (blue) scored worse than standard varieties (orange) in various criteria.
Implications for Society
The capacity for ChatGPT to reinforce linguistic discrimination towards non-standard English speakers presents significant barriers as AI integration into daily life grows. Stereotyping and demeaning responses perpetuate the notion that these speakers possess a lesser command of language, perpetuating societal inequalities.
As language models become increasingly prevalent, users from diverse dialect backgrounds may find themselves marginalized, risking the reinforcement of harmful social dynamics in their interactions with technology.
Discover more about our study: [ Paper ]
FAQ
What is linguistic bias in AI language models?
Linguistic bias refers to the tendency of AI models to favor certain dialects, often resulting in negative stereotypes or misinterpretations when interacting with speakers of non-standard varieties.
How does this bias affect communication?
This bias can lead to misunderstandings, misinterpretations, and ultimately alienation for speakers of non-standard English, hindering their ability to effectively engage with AI tools like ChatGPT.
What are potential solutions to mitigate this bias?
Enhancing training data to include diverse dialects, implementing user feedback mechanisms, and adjusting model responses based on regional language preferences are potential solutions to combat this bias.